检索增强生成(RAG)定义
发布日期:2024/2/29 15:39:58 浏览量:
RAG 的定义可以从其工作流程来概括。图 2描述了典型的 RAG 应用程序工作流程。在这个场景中,用户向 ChatGPT 询问最近发生的一件备受瞩目的事件(即 Ope-nAI 首席执行官的突然解雇和复职),该事件引起了相当多的公众讨论。ChatGPT 作为最著名和广泛使用的LLM,受其预训练数据的限制,缺乏对最近发生的事件的了解。 RAG 通过从外部知识库检索最新文档摘录来弥补这一差距。在这种情况下,它会获取与调查相关的精选新闻文章。这些文章与最初的问题一起合并成一个丰富的提示,使 ChatGPT 能够综合明智的响应。这个例子说明了 RAG 过程,展示了它通过实时信息检索增强模型响应的能力。
从技术上讲,RAG 通过各种创新方法得到了丰富,解决了诸如“检索什么”、“何时检索”和“如何使用检索到的信息”等关键问题。信息”。对于“检索什么”的研究已经从简单的标记开始取得进展 [Khandelwal 等人.,2019]身份检索[Nishikawa 等人.,2022]更复杂的结构,如块[Ram 等人.,2023]和知识图谱[Kang 等人.,2023],研究重点是检索的粒度和数据结构化的水平。粗粒度带来更多信息,但精度较低。检索结构化文本可提供更多信息,但会牺牲效率。 “何时检索”的问题导致了从单一的策略[Wang et al. ,2023e,Shi 等人.,2023]到自适应[Jiang 等人.,2023b,黄等人.,2023]和多重检索[Izacard 等人.,2022]方法。检索频率高带来的信息较多,但效率较低。至于“如何使用”检索到的数据,已经在模型架构的各个级别上开发了集成技术,包括输入[Khattab 等人,2017].,2022],中级 [Borgeaud 等人.,2022],和输出层[Liang et al.,2023]。虽然“中间层”和“输出层”的效果比较好,但存在需要训练、效率低的问题。
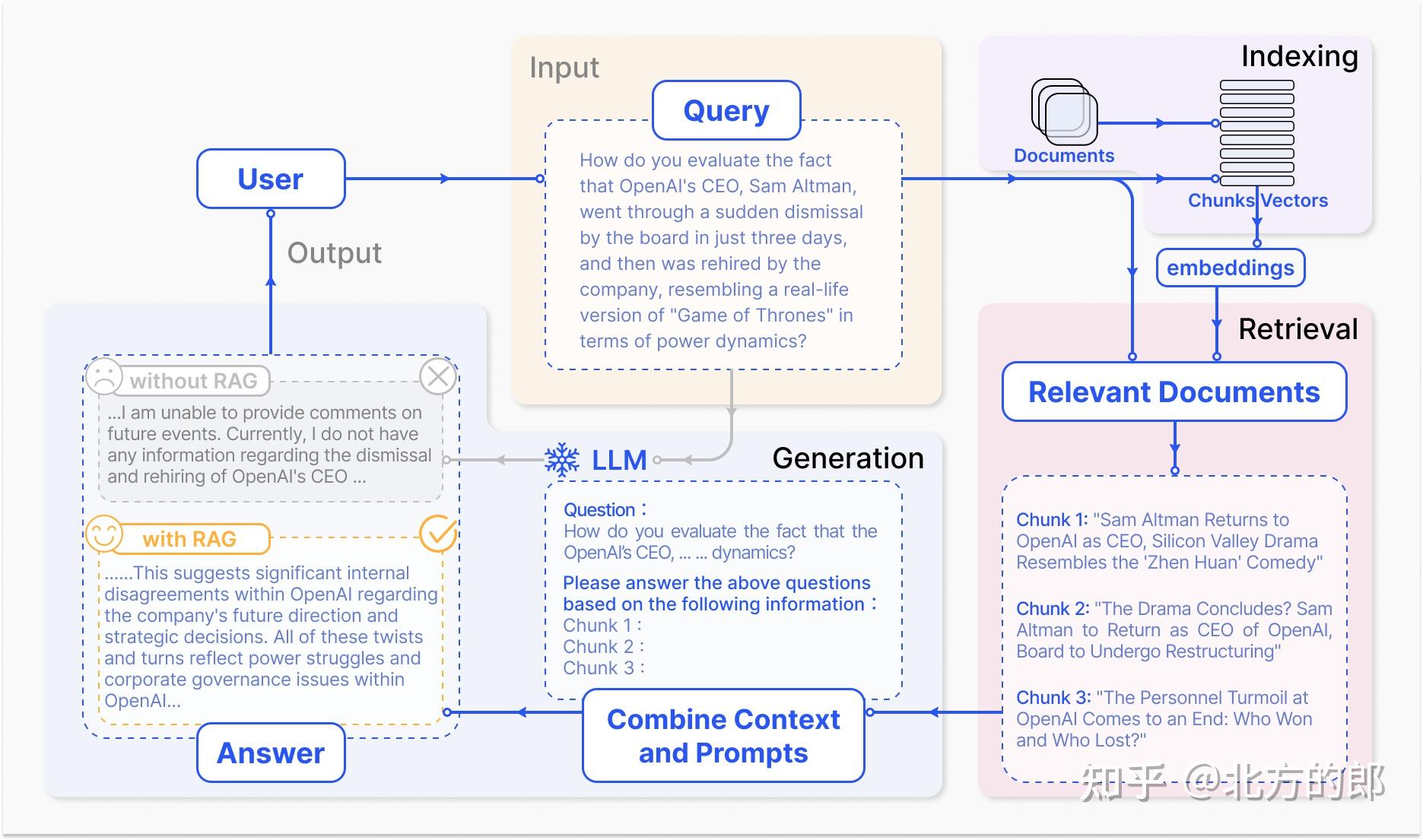
RAG 是一种通过整合外部知识库来增强LLM的范式。它采用协同方法,结合信息检索机制和情境学习(ICL)来提高LLM的表现。在此框架中,用户发起的查询提示通过搜索算法检索相关信息。然后,这些信息将被融入到LLM的提示中,为生成过程提供额外的上下文。 RAG 的主要优势在于它无需针对特定任务的应用程序对LLM进行再培训。开发人员可以添加外部知识库,丰富输入,从而提高模型的输出精度。 RAG因其高实用性和低进入门槛而成为LLM系统中最受欢迎的架构之一,许多会话产品几乎完全基于RAG构建。
RAG工作流程包括三个关键步骤。首先,将语料库划分为离散块,在这些块上利用编码器模型构建向量索引。其次,RAG 根据块与查询和索引块的向量相似性来识别和检索块。最后,该模型根据从检索到的块中收集的上下文信息合成一个响应。这些步骤构成了 RAG 流程的基本框架,支撑着其信息检索和上下文感知生成功能。
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生